Linux 监控及运维

自制 CPU 主频监视器 - 2025-01-30 更新
watch -n 1 "cat /proc/cpuinfo | grep MHz | awk '{print \$1 NR \$3 \$4 \$2}'"
引言
之前经常听身边的 SRE 同事聊线上故障及处理过程,觉得很有意思,最近离职后有时间,我也想仔细了解学习下 Linux 系统的状态监控及运维方面的内容,就写了这边文章,本文侧重于记录 Linux 中与监控运维相关的命令行工具的使用方法及一些小技巧,不涉及 Prometheus 及 Node Exporter 等监控工具。
本文主要面向以下两个问题:
- 如何判断当前服务器的运行状态是否正常?
- 如何获取某一个的服务(进程)的资源占用情况?
初探
当首次登入一个 Linux 系统后,可能会想先了解下眼前这个系统的软硬件信息,比如,是什么发行版?CPU 有几核?内存、磁盘有多大?
查看当前 Linux 系统的内核版本。
uname -r
cat /proc/version
查看当前 Linux 系统属于哪一个发行版。
cat /etc/os-release
# 只适用于支持 LSB(Linux Standard Base)的发行版,Arch、Gentoo 等发行版默认不支持 LSB
lsb_release -a
查看 CPU 信息。
# 查看 CPU 信息
cat /proc/cpuinfo
lscpu
# 查看 CPU 核心数量
grep -c 'model name' /proc/cpuinfo
查看内存大小及使用情况。
free -h
cat /proc/meminfo
查看磁盘大小及使用情况。
# 列出系统中文件系统的磁盘使用情况
# df 关注文件系统
df -h
# 查看某一个文件夹占用的磁盘大小
# df 关注文件
du -h -d 0 ${path_to_dir}
# 列出系统中所有块设备的信息,包括硬盘和分区
lsblk
# 列出系统中所有磁盘及分区的详细信息
sudo fdisk -l
系统负载
对于系统负载,本文主要关注 CPU、内存、I/O、网络这 4 个方面的负载情况。
CPU 与内存
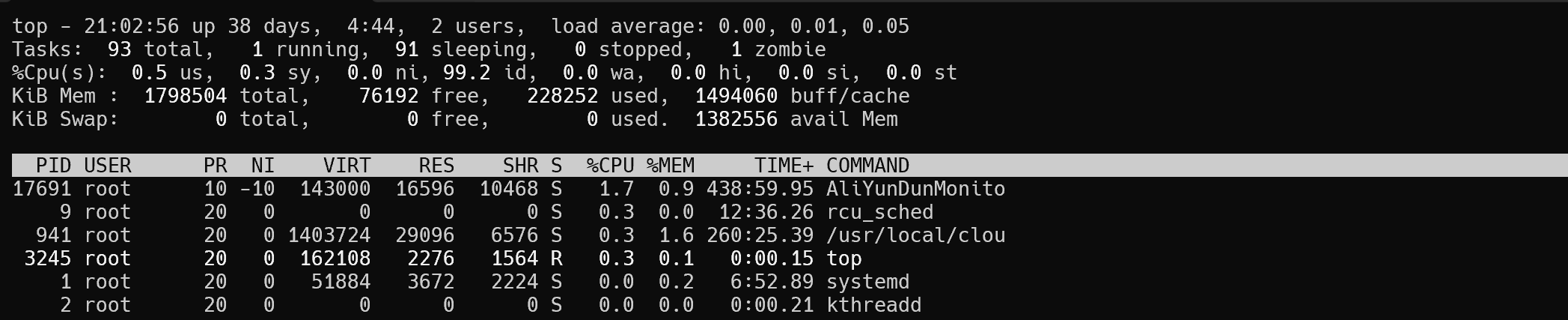
对于如何查看 CPU 与内存的负载,我最先想到的是 top 工具,大多数 Linux 发行版都会预先安装这个工具,但我一直没有深入研究过,top 工具可用于查看当前系统的 CPU 与内存负载情况,top 工具的默认输出可以分为上下两部分,上面部分是系统的负载概览(在 manual 中为 SUMMARY Display),下面部分是每个任务的负载情况(在 manual 中为 FIELDS / Columns)。
负载概览
# 可使用此命令查看这部分相关字段的说明
man -P "less -p '^2\.\sSUMMARY\sDisplay'" top
top 工具默认输出的第一行与 uptime(/usr/bin/uptime)工具的输出是一致的,关于 load average 可以参考理解Linux系统负荷。
在 top 工具中,task(即 process 或 thread)被分为 running、sleeping、stopped 及 zombie 这 4 种状态。那为什么没有 ready 状态呢?在 manual 中能够找到下面表述,即 running 状态已包括 ready 状态。
Tasks shown as running should be more properly thought of as ready to run.
- sleeping:在等待某个事件发生(I/O 事件)或某个条件满足的 task。
- stopped:可通过向进程发送
SIGSTOP或SIGTSTP信号(即按ctrl+z)使其进入 stopped 状态,对于接收到SIGTSTP信号进入 stopped 状态的进程,可通过jobs命令查看,可通过向进程发送SIGCONT信号唤醒进程,命令fg #id可唤醒进程并在前台执行,命令bg #id可唤醒进程并在后台执行。 - zombie:task 已终止,但资源未被回收。
对于内存,top manual 未给出 buff/cache 及 avail Mem 的定义,这里具体可以参考man free。
- buff/cache:是 kernel buffer、page cache 及 slab 使用的内存总和。
- avail Mem:在不使用交换内存的前提下,可用于启动新应用程序的内存大小。
关于 avail Mem 有两个参考链接:
- What do the “buff/cache” and “avail mem” fields in top mean?
- How can I get the amount of available memory portably across distributions?
任务负载
top 的 manual 中会经常看到 SMP(对称多线程),比如,在 SMP 环境下,进程的 %CPU 会大于 100。
# 可使用此命令查看这部分相关字段的说明
man -P "less -p '^3\.\sFIELDS\s/\sColumns'" top
%MEM - simply RES divided by total physical memory
- PR 代表优先级(Priority),如果为数字,越小优先级越高(默认为 20),如果为 rt,表示当前任务的优先级为 real time scheduling priority,具有比普通任务更高的优先级。
- RES 表示常驻内存大小(Resident Memory Size),当前任务所使用的非交换物理内存的大小。
- SHR 表示共享内存大小,可由多个任务共享,比如动态链接的共享库,SHR 为 RES 的子集。
- VIRT 表示任务使用的虚拟内存总量,包括所有代码、数据和共享库,以及已交换出的页面和已映射但未使用的页面。
一些小技巧
- 按
1可查看每个 CPU 核心的负载情况。 - 按
f可以进入配置界面,设置展示哪些字段,及按照哪个字段排序,具体可查看 manual 4.c 小节。 - 可以通过按
c使列 Command 在 name 与 command line 模式间切换。 - 可以通过按
shift+h在进程模式与线程模式间切换。 - 可以通过按
shift+e切换 SUMMARY Display 部分内存展示单位;按e切换 FIELDS / Columns 部分内存展示单位。
补充
top-liked tool family in Linux
top manual 里有一段对于 Linux 内存的描述很棒,可以通过下面命令查看。
man -P "less -p '^\s{3}Linux\sMemory\sTypes'" top
I/O

iotop 工具可用于实时查看 I/O 负载,但可能需要手动安装,发行版可能不会预先安装,iotop 工具的默认输出也同样分为上下两部分,上面部分是概要信息,下面部分是每个任务的 I/O 负载情况。
iotop 的 manual 比较简单和清晰,后面对于每个部分的介绍就直接粘贴 manual 中的内容了。
负载概览
From iotop manual
- Total DISK READ and Total DISK WRITE values represent total read and write bandwidth between processes and kernel threads on the one side and kernel block device subsystem on the other.
- Actual DISK READ and Actual DISK WRITE values represent corresponding bandwidths for actual disk I/O between kernel block device subsystem and underlying hardware (HDD, SSD, etc.).
- Total and Actual values may not be equal at any given moment of time due to data caching and I/O operations reordering that take place inside Linux kernel.
任务负载
From iotop manual
iotop displays columns for the I/O bandwidth read and written by each process/thread during the sampling period. It also displays the percentage of time the thread/process spent while swapping in and while waiting on I/O. For each process, its I/O priority (class/level) is shown.
一些小技巧
- 排序:可以通过按左右箭头键更改排序字段,按
r可以调整排序顺序(从大到小或从小到大)。 - 线程/进程模式:默认是线程模式,按
p可以在两种模式间切换。
系统的网络负载监控(iftop 工具)
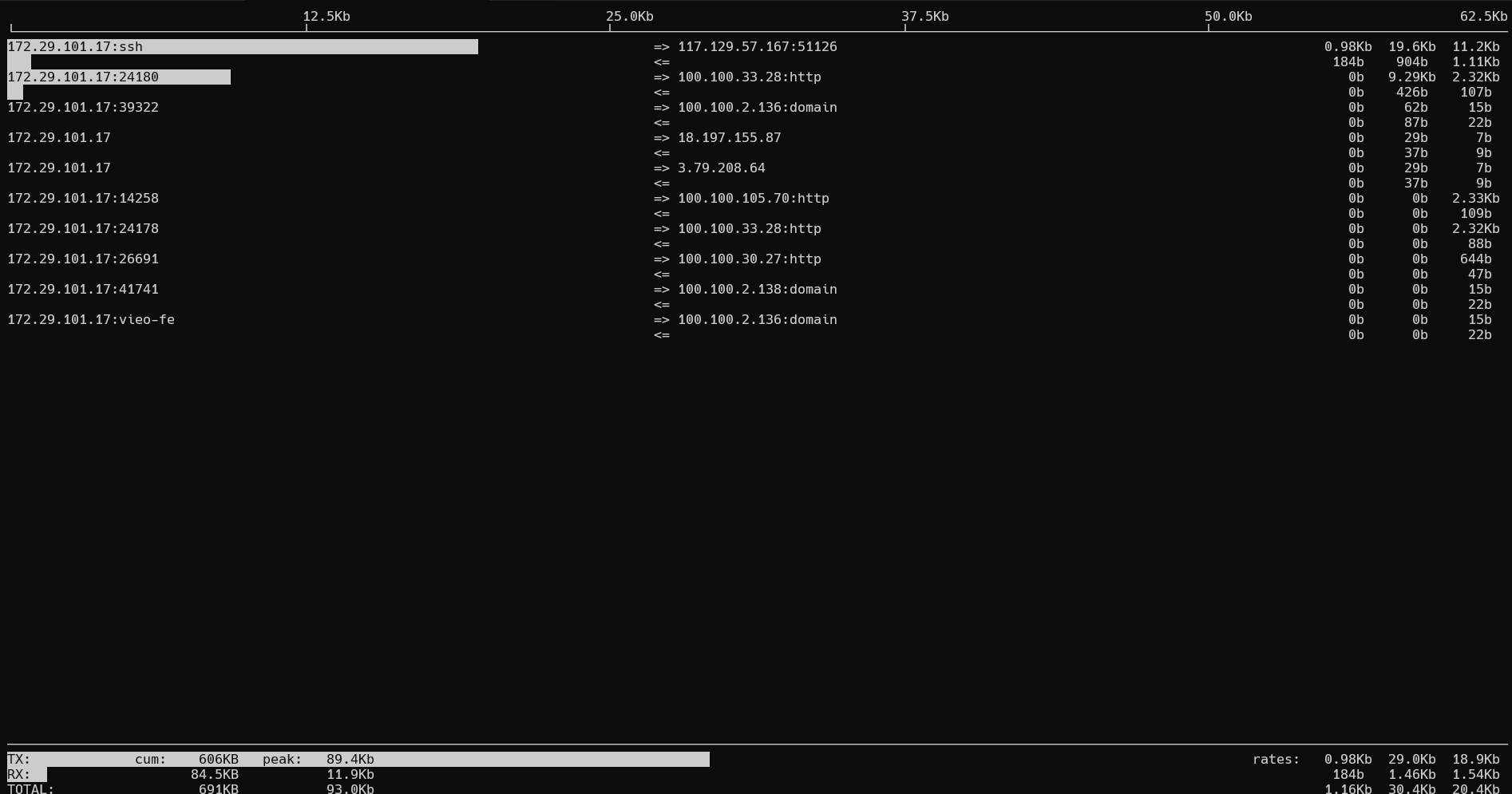
# 查看 eth0 网卡的网络负载
iftop -i eth0
可以通过 iftop 工具查看指定网卡的出入流量,及此网卡与相关站点间的出入流量情况。iftop 工具的默认输出同样分为上下两部分,上下两部分最右侧的三列数据皆表示在 2s、10s 及 40s 内的统计值。下面部分的 cum 表示自 iftop 开始运行后的流量累计总和。
进程监控
# 监控进程的 CPU 与内存负载
top -p ${pid}
htop -p ${pid}
# 监控进程的 I/O 负载
iotop -p ${pid} -P
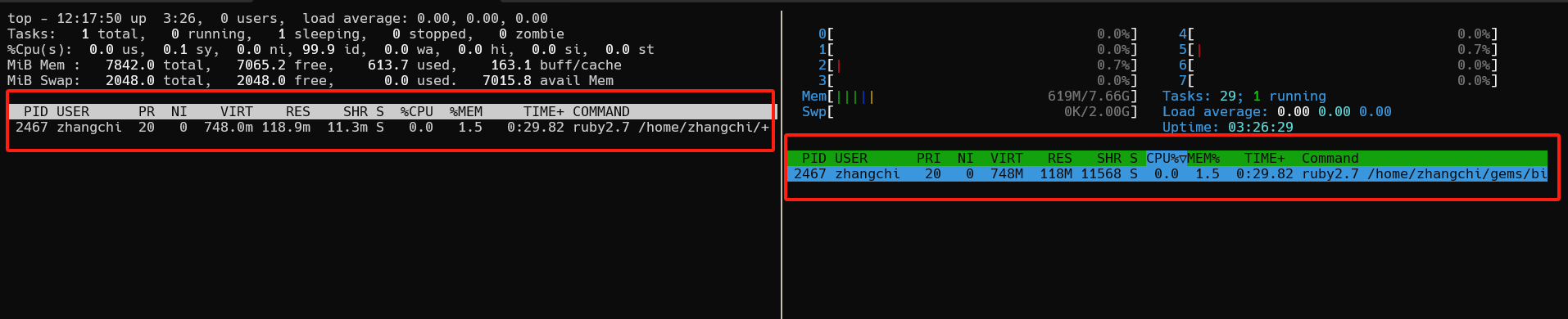

注:关注红色框内的部分,概要部分仍是系统整体的负载情况。
inode 使用情况
Linux 系统监控需要关注 inode 是否(快)被使用完,inode 的详细介绍可参考理解 inode
# 查看 inode 的使用情况
df -i
文件描述符(fd)使用情况
文件描述符也是 Linux 中比较重要的监控项,之前工作中有遇到过文件描述符泄露的案例,系统中创建的文件描述符已达到上限,导致无法再建立网络连接。
介绍
文件描述符的最大数量限制分为下面几种类型:
- 进程级:
- 软限制:当前 Shell 环境能够创建的文件描述符数量不能超过这个值,但普通用户可以修改,修改后的值不能超过硬限制。
- 硬限制:必须有 sudo 权限才可以修改。
- 系统级:所有进程总共创建的文件描述符数量不能超过这个值。
相关命令
# 查看进程级 fd 软限制
ulimit -n
# 修改进程级 环境 fd 软限制
ulimit -n ${value}
# 查看进程级 环境 fd 硬限制
ulimit -Hn
# 修改进程级 环境 fd 硬限制
ulimit -Hn ${value}
# 查看当前系统 fd 限制
cat /proc/sys/fs/file-max
sysctl fs.file-max
# 查看当前系统的 fd 分配情况
# The three values in file-nr denote the number of allocated file handles, the number of allocated but unused file handles, and the maximum number of file handles.
cat /proc/sys/fs/file-nr
# 修改当前系统的 fd 限制
# method 1(永久修改):修改 /etc/sysctl.conf
# 添加或修改下面内容
fs.file-max = ${value}
# 应用配置
sudo sysctl -p
# method 2(临时修改)
sudo sysctl -w fs.file-max=${value}
网络
# 根据 PID 查看某个进程占用的端口号
lsof -i -a -p ${PID}
# 查看某一个端口的连接统计
netstat | grep ${port_num}
# 查看某一个端口是被哪个进程占用的
lsof -i: ${port_num}
之前面试被问到,如果在服务器中有很多 TCP 连接都处于 TIME_WAIT 状态,此时应该如何处理?
这里首先要知晓:
- 处于 TIME_WAIT 状态的 TCP 连接的文件描述符已释放,不会占用文件描述符,即不会耗费文件描述符资源,比较
lsof -i -p ${pid} -a与netstat | grep ${port_num}的运行结果可以看出。 - 只有主动断连的一方才会进入 TIME_WAIT 状态。
导致这种情况的原因可能是因为服务端与客户端间的通信使用短链接,服务端处理完来自客户端的请求后马上关闭连接。
这种情况有什么危害?对于服务端,主要是系统资源的浪费,不用的 tcp 连接长时间不被回收,会占用网络协议栈资源,但端口资源不存在浪费,因为服务端只监听一个端口,端口资源的浪费存在于客户端。
解决或缓解这种情况的办法:
- 服务端与客户端之间使用连接池技术复用连接,且使用长连接,长期来讲,这是比较好的解决方案。
- 调整 Linux 系统配置,减少 TIME_WAIT 的持续时间,可以在短时间内缓解这种情况。