关于并发
前言
最近看完了 OSTEP 的并发部分,想写一篇博客作为回顾,并发对我而言是一个很大很深奥的话题,甚至不知道该从何写起,这篇博客的逻辑可能会比较乱。在计算机科学领域,我们通常认为并发,要么是多个任务1被分配到了不同的 CPU 上,这些任务同时运行;要么是多个任务被同一个 CPU 交替执行,由于交替的速度很快,这些任务看起来似乎是同时运行的。
由于现代操作系统需要协调多个任务的并发执行,现代操作系统可能是最早当然也是最典型的并发程序。对于操作系统的理论研究者,并发绝对是一个绕不开的话题。
这篇博客主要从 Linux 和 C 语言的角度,阐释一些并发相关的知识。
困惑
工作之后,我也经常会编写一些并发程序,但一直对并发程序背后的原理有一些困惑,主要有以下几个方面:
- 并发程序的内存结构是怎样的?比如线程的栈内存是如何分配的?
- 这样的程序会被编译成怎样的汇编代码?
- 操作系统和 CPU 是如何交互的,即操作系统是如何让多个任务被同一个 CPU 交替执行的?或者是如何将多个任务分配到不同的 CPU 的?
问题 1:线程的内存分布
在 stack overflow 看到一则关于线程内存分布的回答(链接),感觉很棒。大概意思是讲,我们可以把进程视为一个持有操作系统资源(比如,套接字)且相互隔离的容器,线程能够在这个容器中运行,并且与这个容器内的其他线程共享这个容器中的资源,线程才是 CPU 执行的基本单元,对于早期 UNIX 系统,在一个进程中只会有一个线程(主线程,在 C 语言中,可以认为是 main 函数的执行体),可以称为 1:1 模型,对于现代 Linux 系统,在一个进程中可以有多个线程,可以称为 1:N 模型。这里体现了操作系统的一些理念,引入进程概念的重要原因之一是资源隔离,而线程是为了提高程序的运行效率2。
线程的内存分布基本如下图所示3,其中,粉色区域为每个线程的栈空间,黄色区域为所有线程共享。由于 ASLR 技术,各个区间内存分布的起始地址是随机的,但相对顺序不变。除主线程外,其他线程的栈空间会在堆上创建。
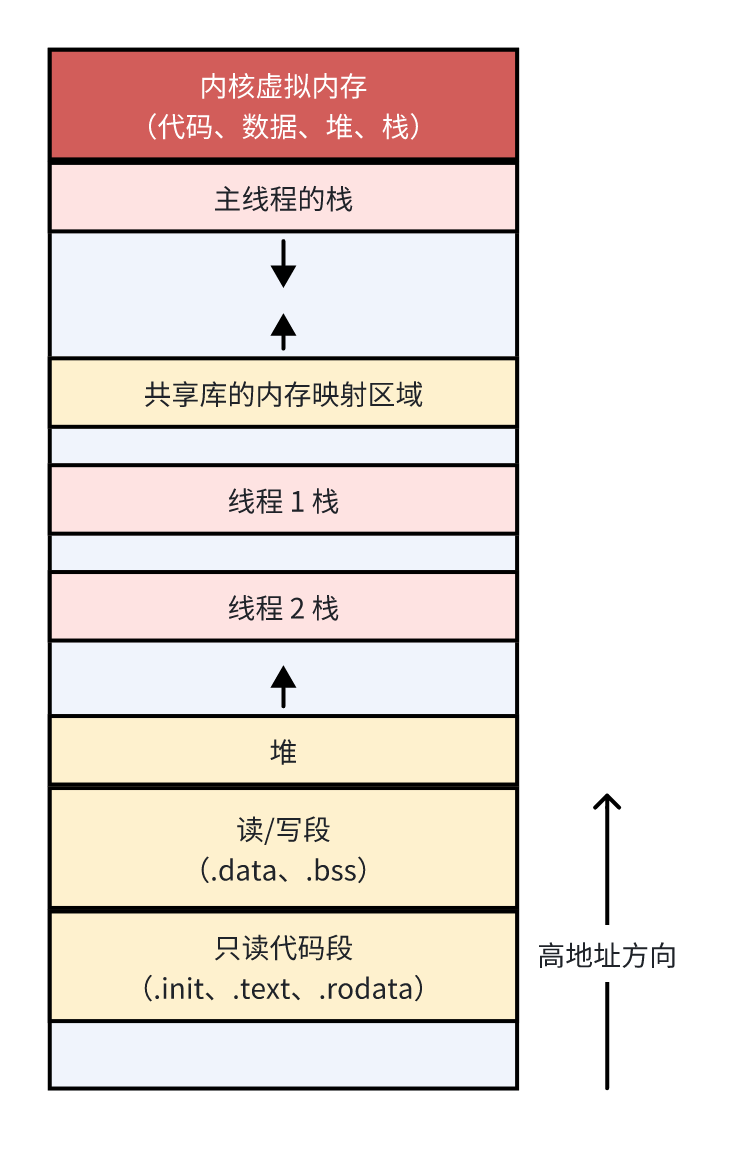
可以通过下面指令和代码试探线程栈在内存中的位置。
# 查看当前进程的内存分布
cat /proc/${pid}/maps
# 查看当前进程中的线程的内存分布
cat /proc/${pid}/task/${tid}/maps
/*
How to use this code?
- Compile: gcc -o mem-layout-test main.c -Wall -pthread -g
- Run: ./mem-layout-test
*/
#include <assert.h>
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
#define Pthread_create(thread, attr, start_routine, arg) \
assert(pthread_create(thread, attr, start_routine, arg) == 0);
#define Pthread_join(thread, value_ptr) \
assert(pthread_join(thread, value_ptr) == 0);
#define MINUTE 60
void *mythread(void *arg) {
int local_var;
// Print the variable's memory address
printf("thread: %s, stack address: %p\n", (char *)arg, (void *)&local_var);
while (1 == 1)
sleep(5 * MINUTE);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
return 0;
}
问题 2:并发程序的机器级表示
系统调用简介
首先以 x86_64 架构 Linux 系统为例介绍下系统调用的原理,系统调用是由软硬件共同完成的,x86_64 架构提供了syscall指令发起系统调用4,当执行系统调用时,需要先将系统调用的编号5存入%rax寄存器,系统调用的具体参数放入其他寄存器中,然后 CPU 执行syscall指令,在执行时,CPU 主要工作如下:
- 将 CPU 权限级别(CPL,CPU Privilege Level)从用户态(CPL 3)切换为内核态(CPL 0);
- 保存用户态的返回地址;
- 将程序计数器
PC设置为寄存器MSR_LSTAR(Model-Specific Register - Long System Target Address Register)中的地址,MSR_LSTAR寄存器保存了内核系统调用处理程序的入口地址。
然后 CPU 根据%rax寄存器中的系统调用编号,找到对应的系统调用处理程序并执行。
线程是如何创建的
线程可以视为一个正在运行的实体,在 Linux 内核代码中,使用 task_struct 结构体表示这个实体,它也是我们常讲的 PCB 或 TCB,对于版本 4.19.307,这个结构体定义在 include/linux/sched.h 597 行,当我们使用系统调用 API 创建一个线程时,实际会创建一个 task_struct 结构体,并放入操作系统的任务队列中,由调度器分配 CPU 资源执行。
如果用 GDB 调试代码 1,可以得到由图(a)至图(d)的调用过程,从图中可以看出libc的pthread_create方法最终使用了clone3系统调用创建线程。
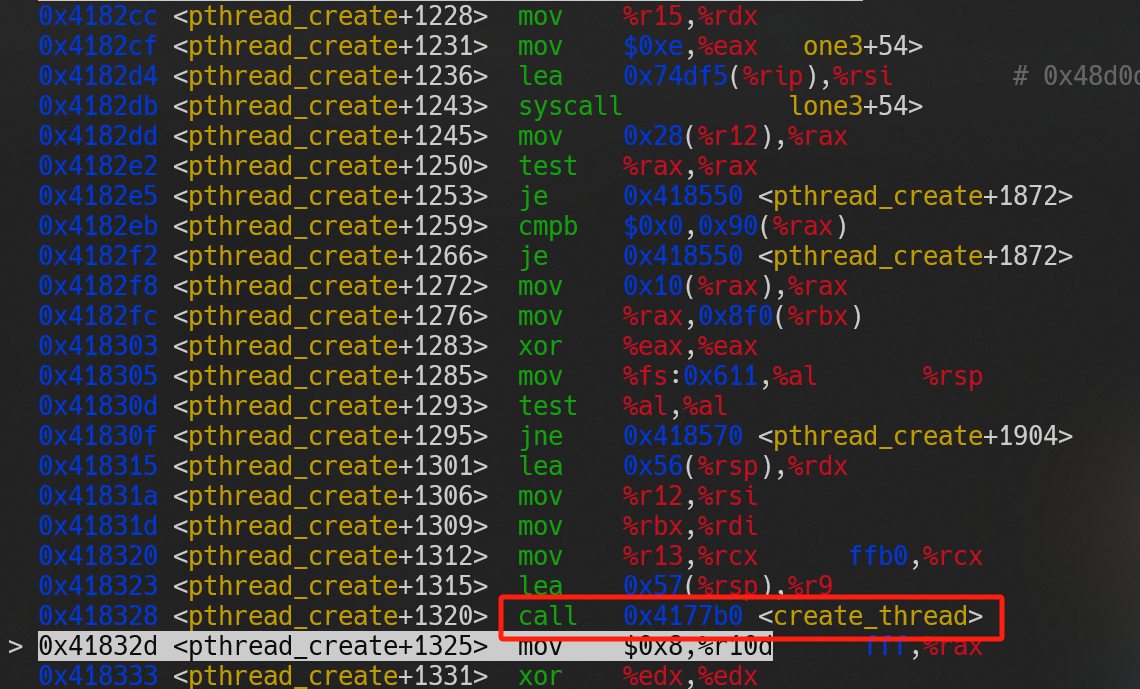 (a) |
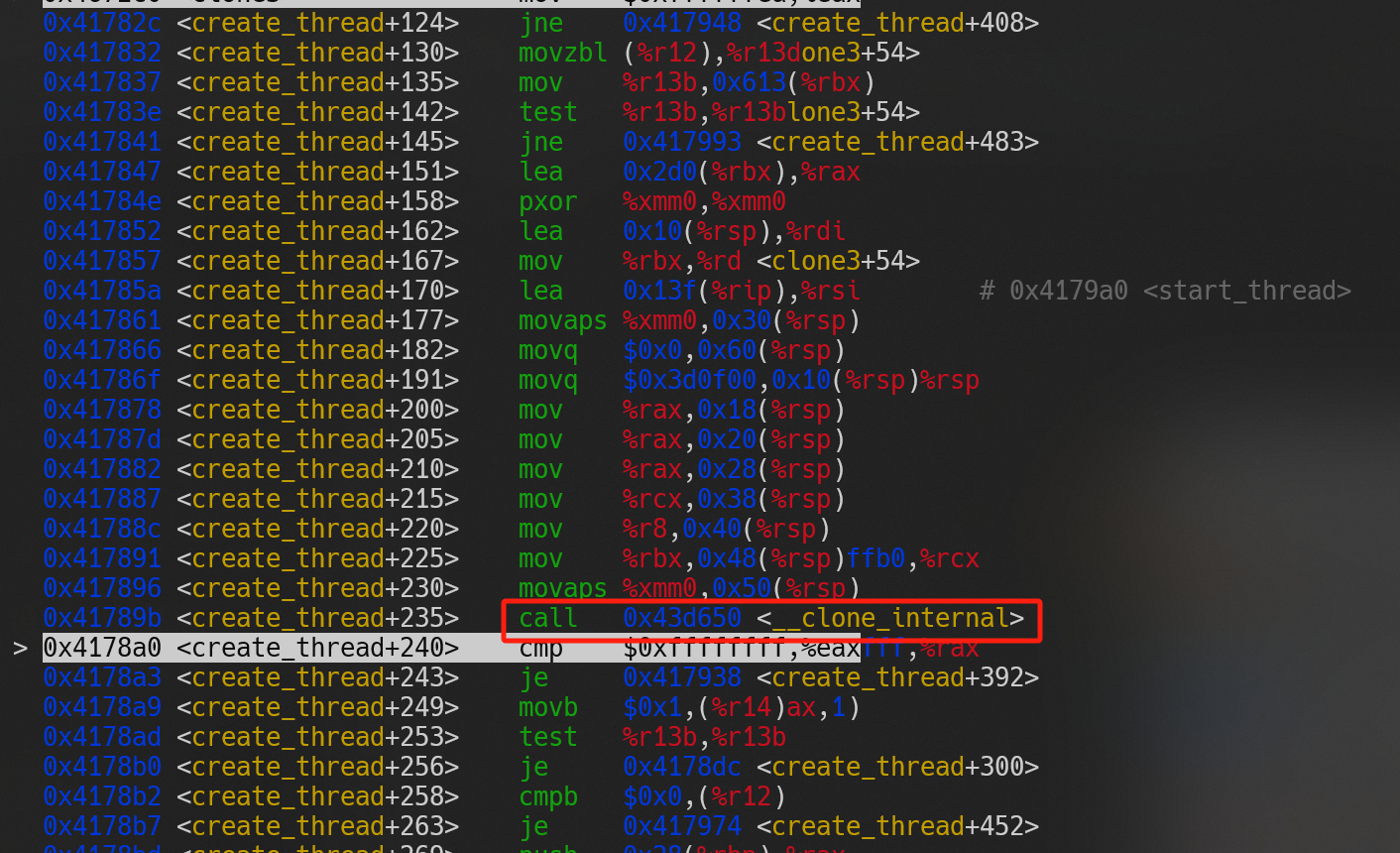 (b) |
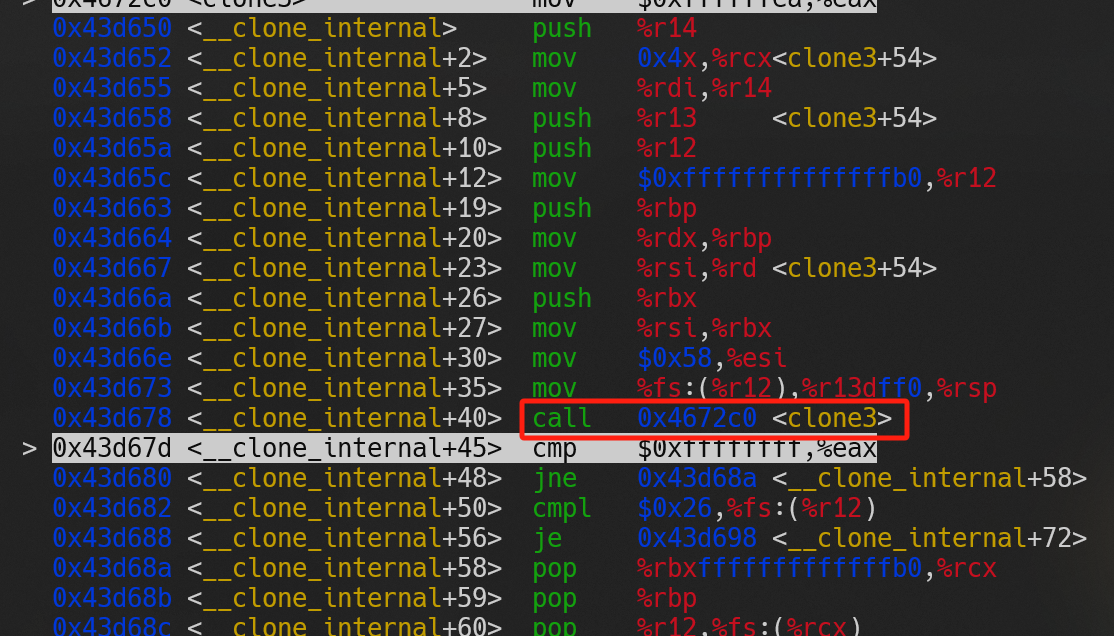 (c) |
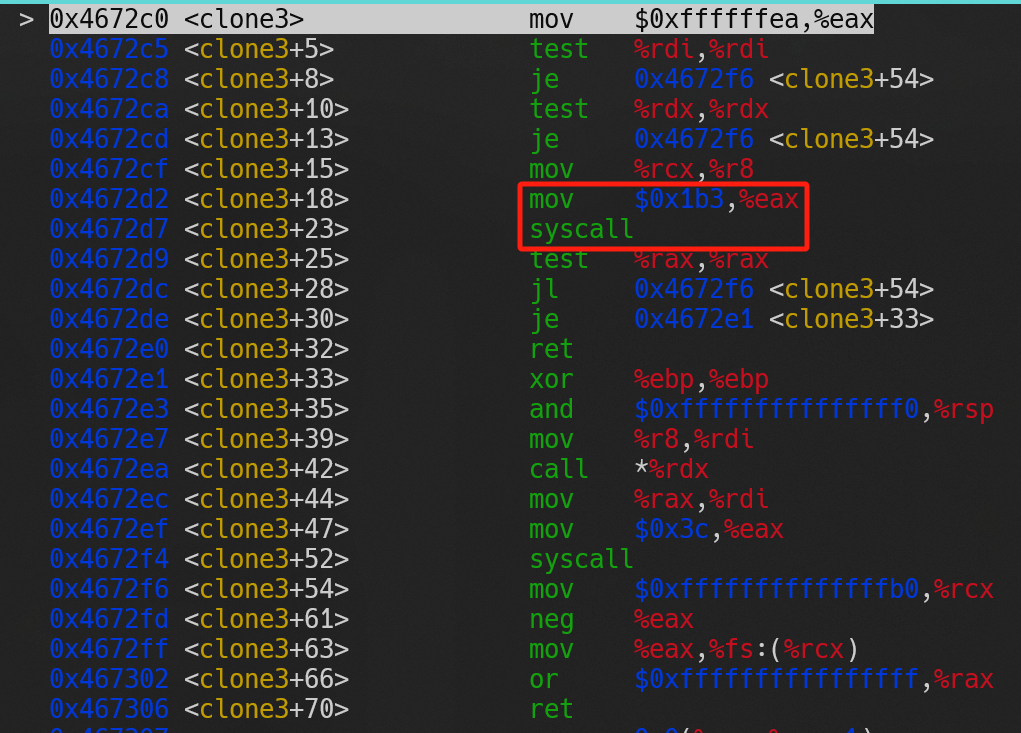 (d) |
# GDB 使用方法
# 用 GDB 打开二进制文件
gdb ./mem-layout-test
# 在 GDB 中设置断点并执行
(gdb) break pthread_create
(gdb) run
# 单步执行,观察 pthread_create 的执行逻辑
(gdb) si
# 如果想立即执行并退出当前函数,可用:
(gdb) finish
问题 3
这个问题我目前还回答不了,这里需要了解操作系统的调度器原理以及操作系统与 CPU 硬件是如何交互的。
有一点可以记录下,操作系统是通过中断维持自己的计算机系统管理者地位的,通过定时中断,计算机系统会定时执行操作系统内核中的中断处理程序,将控制权交给操作系统。
如何实现互斥锁
对于 x86 架构,下面代码分别基于cmpxchgl与xchg两种汇编指令实现了互斥锁。
/// How to Use Inline Assembly Language in C Code?
///
/// https://gcc.gnu.org/onlinedocs/gcc/extensions-to-the-c-language-family/how-to-use-inline-assembly-language-in-c-code.html
/// https://stackoverflow.com/questions/71625166/trying-to-implement-a-spin-lock-via-lock-xchg-assembly
#include "common_threads.h"
#include <bits/pthreadtypes.h>
#include <stdio.h>
#include <string.h>
#define LOCK 1
#define UNLOCK 0
typedef volatile int vint;
static vint counter = 0;
static vint lock_t = 0;
int cmpxchgl(int expected, vint *status, int new_value) {
asm volatile("lock cmpxchgl %2, %1"
: "+a"(expected)
: "m"(*status), "r"(new_value)
: "memory", "cc");
return expected;
}
int xchg(vint *addr, int newval) {
int result;
asm volatile("lock xchg %1, %0"
: "=r"(result), "=m"(*addr)
: "0"(newval), "m"(*addr)
: "memory");
return result;
}
void lock_cmpxchgl(vint *lock) {
while (cmpxchgl(UNLOCK, lock, LOCK) != UNLOCK)
;
}
void unlock_cmpxchgl(vint *lock) {
asm volatile("movl %1, %0" : "=m"(*lock) : "r"(UNLOCK) : "memory");
}
void lock_xchg(vint *lock) {
while (xchg(lock, LOCK))
;
}
void unlock_xchg(vint *lock) { xchg(lock, UNLOCK); }
void *mythread(void *arg) {
printf("%s: begin\n", (char *)arg);
for (int i = 0; i < 1e7; i++) {
lock_cmpxchgl(&lock_t);
counter++;
unlock_cmpxchgl(&lock_t);
}
printf("%s: end\n", (char *)arg);
return NULL;
}
int main(int argc, char *argv[]) {
if (argc > 1 && strcmp(argv[1], "test_xchg") == 0) {
lock_xchg(&lock_t);
printf("lock: lock_t: %d\n", lock_t);
unlock_xchg(&lock_t);
printf("unlock: lock_t: %d\n", lock_t);
return 0;
}
if (argc > 1 && strcmp(argv[1], "test_cmpxchgl") == 0) {
lock_cmpxchgl(&lock_t);
printf("lock: lock_t: %d\n", lock_t);
unlock_cmpxchgl(&lock_t);
printf("unlock: lock_t: %d\n", lock_t);
return 0;
}
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: end (counter = %d)\n", counter);
return 0;
}
参考与脚注
-
文中的任务是一个统称,指具有独立执行点的单位,可以是进程、线程或者协程等。 ↩
-
想起之前看到过这样一句话,运维的本质在于资源的隔离,不在于资源的扩充。 ↩
-
主要参考 CS:APP 9.7.2 小节与 OSTEP 26 节第 2 页,对于图中细节可参阅这两部分。 ↩
-
详细可参阅 System V Application Binary Interface AMD64 Architecture Processor Supplement A.2.1 小节。 ↩